
个性化搜索引擎中用户兴趣建模研究
|
陈利国 郭琼琼 张新红 郑州铁路职业技术学院 摘要:当今社会搜索引擎已经成为人们从互联网获取信息的主要途径,但很多时候搜索的精度却不能满足用户的要求。比如搜索结果信息量庞大用户很难找到自己需要的信息,或者搜索结果根本不包含用户关注内容等等。因此,本文提出一种以用户兴趣为前提的建模方案,并对搜索结果按用户兴趣进行排序,帮助用户高效地从网络中获取信息。 关键词:个性化搜索引擎,用户兴趣,建模 个性化搜索引擎,实质上就是一种以用户需求为中心的搜索引擎服务。首先它学习不同用户访问网络的特性,创建用户访问模型。然后根据不同用户的不同需求,不断调整服务内容以适应不同用户的个性化需求。个性化搜索引擎的核心是用对户兴趣的建模。只有对用户兴趣、访问特点等信息进行正确的分析,并准确的描述为计算机可以理解的形式后,搜索引擎才能真正实现以用户需求为中心的个性化搜索与服务 一、 用户兴趣的来源与获取 1、用户兴趣的来源 对用户兴趣进行建模,首先我们要了解用户兴趣的来源有哪些。通过对用户使用网络获取信息的全过程的分析可以发现,用户访问互联网的过程共有以下几种信息: (1) 用户的收藏夹。一般用户会把感兴趣和重要的页面保存在收藏夹中便于下次使用,所以收藏夹可以反映用户的兴趣。但也存在问题,因为和用户浏览的总页面相比,用户收藏夹中的页面数还是相当少的。 (2) 用户的浏览行为。如用户保存某个页面或者印某个页面;用户下载图片或视频信息;用户在某网页上长时间驻留;用户复制网页上的文字等等。这些行为都可以说明用户对该网页内容感兴趣。 (3) 用户手工输入的信息。如用户在搜索引擎中输入的关键字、在网页导航中选择特定的栏目等等。这些用户手工输入的信息都能很好地表示用户的兴趣,是用户兴趣建模的重要信息来源。 (4) 服务器日志。用户浏览的页面以及用户在访问过程中的行为,都在日志服务器中有详细的记录。因而服务器日志可以反映用户的兴趣。 2、用户兴趣的获取 获取用户兴趣信息的方式有两种:显示获取和隐式获取 (1) 显式获取 显示获取要求用户主动提供能够反应用户兴趣的信息。如用户搜索的关键词、 选择的领域栏目等。或者要求用户以反馈的形式发表对浏览页面的感兴趣程度或满意程度。显示获取有准确率高、易于实现等特点。但此方法要求用户不断与系统交互,对用户正常使用网络有一定干扰,降低了用户使用系统的积极性。 (2) 隐式获取 隐式获取方式不需要用户提供兴趣信息,在不干扰用户正常使用网络的前提下获取用户感兴趣的信息。和显示获取方式相比,隐式获取的信息有大量的冗余和无用信息,精确度不如显示获取方式高。另外隐式获取涉及个人隐私等问题,遭到一定程度的排斥 二、用户兴趣的表示方法 用户兴趣的表示方法对用户建模至关重要,好的表示方式能够更真实的反应用户信息,并有利于后面建模方法的选取,主要有一下几种常见表示方法: (1) 主题表示法 主题表示法通过用户关注信息的主题来表示用户模型。如用户关注教育和财经,用户模型则表示为(教育,财经)。该表示方法一般结合相应的应用领域使用。假设用户在搜狐网定制了教育和IT频道,搜狐网把该定制记录下来,当作用户模型。用户下次登录搜狐网时,网站会根据已有的用户模型来定制页面,显示用户关注的内容。 (2) 收藏夹表示法。 收藏夹中存有用户感兴趣的内容或用户认为重要的内容。收藏夹表示法以用户使用的收藏夹来表示用户模型。 (3) 关键词列表表示法 关键词列表表示法以用户所关注信息的关键词来表示用户模型。假设用户对羽毛球赛感兴趣,那么用模型可表示为(世锦赛,汤姆斯杯,黄金大奖赛,林丹,李宗伟,马琳)关键词可以由用户指定,也可以通过学习获得。 (4) 基于向量空间模型的表示方法。 基于向量空间模型的表示方法通过关键词向量空间中的向量来表示用户模型。向量空间模型是文档表示的常用方法。 三、用户兴趣建模 用户输入的查询关键字是用户兴趣的直接表示,但是其信息量较少,并且由于同义词、一词多义的情况使得单纯依靠查询关键词建立用户兴趣模型并不可靠。若同时从查询关键字、用户感兴趣的搜索结果入手,建立用户兴趣模型,在一定程度上解决了上述问题。而实际上,用户的兴趣受文化氛围、职业、学历、年龄等多方面的影响,加之现今的教育体制、职业领域等诸多环境都极为相似,所以说具有相似用户兴趣的用户必定存在,而且相对稳定。 1、兴趣节点的表示 所谓兴趣节点就是用户在一次查询过程中的行为信息集合,它是用户建模的基础。本文中的兴趣节点用四元组KU={st,keyword,url,fb}表示。其中st表示搜索时间,keyword表示用户曾经搜索的关键字;url为针对查询关键字keyword所返回搜索结果的地址,其通常是一个url列表,如:url={url1,url2,…,urln}。通常这个url列表是十分大的,对于商用搜索引擎通常达到几十万条。对于研究用户兴趣而言,那么大数据量是毫无必要的。在这里我们只选取用户可能感兴趣的前m条相关结果的url地址;fb表示针对查询关键字keyword,用户对搜索结果url的满意程度。现实中用户的兴趣是在不断变化的,例如用户很可能因为工作变换的原因使兴趣由C++转向java,同时某些新需求的出现也会导致用户突然对某个领域,如体育、教育等产生兴趣。所以要定期扫描户记录,删除较为陈旧的信息记录,更新用户的兴趣点。 2、用户兴趣到类别的映射 用户兴趣到类别的映射用IC=(ci,wi)表示,其中c为categorization的缩写,表示类别i,wi表示用户在类别i上的兴趣倾向,即兴趣权重。其计算方法如下: 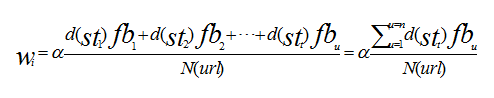 其中d(st)表示用户反馈信息随着时间的推移,其影响变得越来越小,n表示某用户所感兴趣的url中类别为i的个数,fbi为用户对类别为i的url反馈值。N(url)表示用户在所有类别中感兴趣的url个数。a为调节因子,主要用来描述用户注册信息,如职业、专业对兴趣的影响。 3、排序算法 个性化搜索引擎的最终目的是将最符合当前用户兴趣的信息排在返回列表的最前面。在PageRank算法中对于链出的权值贡献是平均的,而出于商业利益或竞争因素,绝大多数Web页面都不会指向其竞争领域的页面;另外,像谷歌、百度等权威主页也都没有给出搜索引擎的相关描述信息。而HITS算法计算量比PageRank算法大,花费时间较长,难以满足用户需求。更重要的是以上算法都没有考虑到用户之间的差异,而用户之间的差异将直接影响搜索引擎的准确度。因此只有充分考虑用户的差异,才能根据不同用户返回不同的结果。让用户得到真正需要的信息,达到较高的准确度。因此本文提出了基于用户组反馈的排序算法,其具体步骤如下: 第一步,将用户注册信息采用向量空间表示,如{(出生日期,日期),(性别,男/女),…,(学历,初中/高中/大学..)}; 第二步,采用余弦方法,计算用户信息之间的相似度计算,取得最为相近的前m个用户,记为集合U。 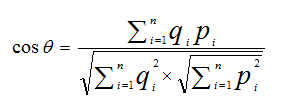 其中p,q分别为对应的向量空间。 第三步,将集合U中的用户兴趣模型向量与当前搜索用户的兴趣模型向量继续利用余弦公式进行比较,并过滤出集合G,即用户组G。 第四步,采用公式重新排序搜索结果;
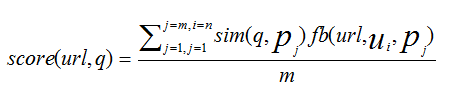 其中,sim(q,p)表示示当前查询关键字q与其他用户中历史查询记录p的相似程度, fb(url,u,p)表示用户u对该关键字p搜索到的结果url的反馈值。m表示与查询关键字相似的历史查询记录的个数。该算法利用用户兴趣组中其他用户的相似查询反馈实现对某个搜索结果的反馈信息。所谓相似查询,即用户兴趣相似的用户使用相同或相似关键字进行查询。 结语 本文介绍了用户兴趣的来源、获取和表示方法。并提出一种基于用户兴趣的建模方案,该方案采用四元组表示用户兴趣,并将用户兴趣映射到相对稳定的类,最后通过基于用户兴趣的排序算法对结果进行排序,优先返回用户真正需要的数据,实现个性化搜索。本建模方案具有一定的理论意义和实践意义。 参考文献 [1]韩旭.个性化推荐系统用户兴趣建模方式的研究[J].数字技术与应用,2010(11) |



 村改居背景下农村
村改居背景下农村 “时间银行”模式
“时间银行”模式 老龄化背景下医药
老龄化背景下医药 浅谈中国K12教育
浅谈中国K12教育 新媒体与产品代言
新媒体与产品代言 高校周边健身房大
高校周边健身房大

{kind=link}