
基于LSTM与熵值----TOPSIS法的投资组合构建策略
|
黄思颖 华南师范大学数学科学学院 摘要:股票市场具有较强的波动性和不确定性,如何利用已有信息构造一个合理的投资组合一直是人们关注的问题。文章观察股票数据以及公司基本数据,确定了预测股票走势的指标数据,再基于LSTM模型预测出所选股票的周涨跌幅,进而将预测的周涨跌幅作为其中一个因子,结合券商研报的最近一期相关数据,使用熵值----TOPSIS法对股票进行打分排序,并据此构建投资策略。最后通过实际数据的验证,说明了文章的模型的有效性。 关键词:LSTM;熵值----TOPSIS法;投资组合构建 一、引言 随着中国经济的发展,国内股票市场的发展也十分迅速,股票是资本市场的重要组成部分,对国家经济发展、投资者而言均有重要的意义。而由于股票市场具有很强的波动性和不确定性,盲目进行投资往往会造成巨大的亏损。对于投资者而言,如何制定一个合理的投资策略,理性进行投资就具有重要的理论意义及现实意义。 目前已有很多学者针对股价预测做了许多工作,包括ARIMA模型预测、SVM模型预测、K-means及马尔可夫预测等等,也有基于长短期记忆网络(LSTM)等多种神经网络方法对股票价格进行预测。而在投资组合的选择方面,多数人采用回归法和打分法等传统的多因子模型,其中打分法的因子赋权方法有等权重法、IC均值加权法和IR_IC加权法等,也有依照主观经验和专家建议来给因子赋权。然而,回归法容易受极端值影响,当因子的敏感度较强时,该方法就不太适合,对模型的效果也存在一定影响;而打分法的因子赋权法在较大程度上依赖于个人,主观性较强,同时,因子的敏感程度与有效性可能会跟随市场风格的变化而变化[1]。综上所述,传统的因子赋权方法或多或少都存在一定的不足之处,在多种现实情况下都不太符合。 除此之外,现有的选股策略所选取的因子大多为公司股票的各种相关历史数据,包括开盘价、收盘价、涨跌幅、换手率等等,而较少的考虑到投资者自身的心理因素影响。基于此,本文将所选取的指标数据分为股票数据以及公司数据,其中股票数据即为股票的各类历史数据,公司数据即为最近一期权威的券商研报所展示的公司相关指标数据,包括投资评级。 因此,为了构建一个客观、稳健的多因子投资策略,本文决定选用熵值——TOPSIS法对特征指标进行赋权,这种赋权方法在一定程度上避免了主观性的影响。文章依据股票指标数据使用LSTM模型预测出未来一周的股票走势,计算得到股票在未来一周的涨跌幅。再将预测出来的股票价格涨跌幅作为其中一个因子,结合最新一次的研报数据,即公司数据对股票进行综合打分,选取涨跌幅大于0且打分排位前五的公司股票,按照打分给定投资比例,最终确定一个客观的、有效的投资策略。 二、数据准备 (一)股票选取 由于券商机构数以及券商研报数较少的股票往往不具有足够高的市场关注度,对这类股票进行分析具有较大的难度,因此,本文优先选择市场关注度高的股票。其次,为了更好地分析特征指标对股票走势的影响,本文选取的时间为2016-11-07至2021-11-05,而有些股票的研报或者开始时间较晚,或者结束时间较早,无法保证数据量的需求及时效性,因此本文同样将这部分股票筛除掉。再次,联系到后文所需要用到的特征指标,在对数据进行初步观察之后,筛除掉一些数值缺失的股票。最后,基于分层抽样的思想,为了使样本的代表性比较好,误差比较小,本文采取选取来自不同行业的股票的策略。 由于股票的走势除了受到公司基本面、研报等因素的影响,还受到许多其他因素的影响,甚至有可能出现某些庄家的操纵,或某些资金利用信息优势进行套利等等,使得股票数据的真实性无法得到保证。因此,在选择股票作为研究对象时,应选取具有足够大体量的公司,在其所处的行业中具有较大的代表性,保证公司的财务安全性,以确保数据的有效性。 为了保证数据获取的准确性以及完整性,减小模型的误差[2],本文选取了十只股票作为研究对象。 (二)特征选取 1.因子的选取
在特征工程中,特征指标的选取对于整个模型的效果具有很大的影响,数据质量的优劣会直接影响模型的效果,因此特征指标的选取具有十分重要的意义。对多因子模型而言,候选因子需要从不同的方面出发衡量,也应具有一定的经济学解释。 一般来讲,可供选取的因子大致分为八类:估值因子、成长因子、盈利能力因子、动量反转因子、交投因子、规模因子、股价波动因子以及分析师预测因子。其中每一类因子都包含有众多指标。估值因子主要反映了公司的价值;成长因子主要反映了公司的发展成长空间的大小;盈利能力因子主要反映了公司的盈利能力的高低;规模因子主要反映了公司的规模大小;分析师预测因子主要反映了分析师对公司未来发展的预测。 本文通过参考大量相关文献,结合各类指标的经济学意义,筛选出了如下候选指标: (1)估值因子:市盈率、市净率、市销率、市现率、企业价值倍数、PEG;(2)成长因子:营业收入增长率、净利润增长率、每股收益增长率;(3)盈利因子:毛利率、净资产收益率、营业费用比例、财务费用比例;(4)动量反转因子:前期涨跌幅;(5)交投因子:前期换手率、量比;(6)规模因子:总市值、流通市值、自由流通市值、总股本、流通股本;(7)股价波动因子:前期股价振幅、日收益率标准差;(8)分析师预测因子:预测净利润增长率、投资评级。 2.因子的IC检验
选定了候选因子后,需要对因子的有效性进行分析。本文选取的是IC检验。IC即信息系数,表示的是各个股票第T期的因子暴露同第T+1期收益的相关系数,代表因子对股票的收益率有较强的解释度, 其计算方法如下所示:[2]  用IC值进行因子的有效性分析,具体分析方法如下:(1)IC值的正负代表因子与收益率呈正相关或负相关;(2)IC值的绝对值越大说明该因子对收益率的解释度越强。 本文以股价波动因子中的前期涨跌幅为例,对数据进行IC分析(本文所用数据均来自choice金融终端)。当IC的绝对值大于0.03甚至0.02即代表因子具有较好的解释力,最终筛选出来的特征指标如下: (1)估值因子:市盈率、市净率、市销率、市现率、企业价值倍数、PEG;(2)成长因子:营业收入增长率、净利润增长率;(3)盈利因子:毛利率、净资产收益率;(4)动量反转因子:前期涨跌幅;(5)交投因子:前期换手率;(6)规模因子:总市值、流通市值、自由流通市值、总股本、流通股本;(7)股价波动因子:前期股价振幅;(8)分析师预测因子:投资评级。 三、数据预处理
本文将筛选出的特征指标划分为两类:股票相关指标和公司相关指标。其分类情况如下表所示: 表1 指标分类
其中股票相关指标对应的是2016-11-07至2021-11-05的日数据(下文简称股票数据),公司相关指标对应的是10家公司的近期数据(下文简称公司数据)。两种数据部分展示如下: 表2 示例股票部分数据
表3 公司数据
(一)缺失值处理
通过简单的数据探查,可以发现部分股票数据含缺失值,出现缺失值的特征列为:涨跌幅、换手率、振幅,其中最大缺失数为4,可以发现缺失值的数量很小,其对模型的影响可以忽略不计,而为了避免LSTM模型输出nan值,这里使用缺失值的上一天数据填充缺失值,这对于时序数据来说是合理的。 (二)特征筛选
本文选取的指标数据之间可能会出现较大的相关性,这对模型的训练及预测都会产生一定的影响,而进行特征降维能够有效提高模型运行效率并精炼数据关系。因此本文利用皮尔逊相关系数检验股票相关指标间的相关性,对于高度相关的指标组(彼此相关性大于0.85),只保留其中一个。 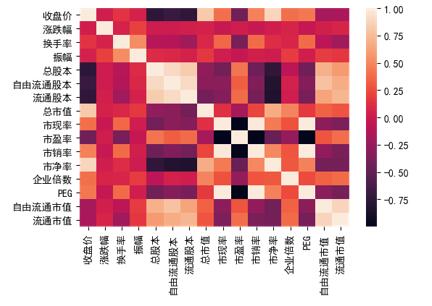 图1 热力图 由热力图或相关性矩阵可以发现下面各组特征间高线性相关:(1)总股本、自由流通股本、流通股本;(2)历史PEG、市现率、市销率;(3)自由流通市值、流通市值。 考虑到各指标的经济意义及其代表性,本文将每组分别保留指标:总股本、市销率、流通市值,其余删去。 (三)特征无量纲化
由于每个指标间描述的信息不同,数值范围也有很大差距,而对于神经网络和综合评价模型来说都需要归一化的数据,因此需要对股票数据和公司数据进行无量纲化。归一化公式为:  (四)深度学习数据集构建
完成对数据的处理之后,本文使用前50天的股票数据,预测后5天的收盘价涨跌情况。因此网络输入为(n,50,5)的矩阵,输出为(n,1,5)的向量。由已搜集的历史数据,可以构建n=1107组样本和标签。选取后20%作为测试集,剩下为训练集。 四、LSTM股价走势预测模型 (一)模型原理 由于传统的循环神经网络RNN在长程记忆上容易发生梯度爆炸和消失的情况,在分析较长的序列类型数据时没有优势,因此本文选择一种优化的长短期记忆网络,LSTM,属于时间递归神经网络。其在传统的循环神经网络的基础上引入了许多门控,避免了梯度减少的问题。通过加入门控结构,可以使网络更加适应长时依赖,避免了梯度消失的问题[3],进而更加符合本文模型的需要。 (二)网络结构 1.输入和输出 输入前50个交易日的股票数据,输出后5个交易日的收盘价。 2.网络隐层数与节点数 对于隐层数和节点数的选择,没有确定性结论或规律,依实际情况而论。本文通过多次更改参数,比较模型损失值(MSE),发现使用多层LSTM模型的总体效果较佳,最终确定层数为4,并添加drop机制增强鲁棒性。 (三)多因子投资策略的构建 通过前文的基本分析,为了构建一个客观、稳健的多因子投资策略,本文决定选用熵值——TOPSIS法对特征指标进行赋权,并由此对股票进行综合打分,最终确定一个客观的、有效的投资策略[4]。具体操作流程如下所示: 1.特征指标的选取
在前文,本文利用LSTM模型预测了未来一周10支股票的走势。为了建立一个合理的投资策略,本文利用未来5天的收盘价计算得到一个特征因子:周涨跌幅预测值,其计算公式为:   (四)模型的求解
在对模型的原理及流程进行简单介绍之后,现在以制定11月1日至11月5日这一周的投资策略为例,对模型进行求解,并将模型计算出来的结果与实际结果进行对比分析,说明本研究的合理性及准确性。 1.股票走势预测
本文首先使用2016年11月7日至2021年10月31日的数据训练(80%)和测试(20%)模型,对不同的股票分别搭建一个模型,最终得到分别对应10支股票的股票走势预测模型,使用Mean_Square_Error(MSE)作为损失函数得到训练和测试的损失曲线如下图所示:
图2 训练和测试的损失曲线(示例) 再将11月1日前50个交易日的股票数据输入股票走势预测模型,得到股票的走势预测如下图所示(此处以E股票的结果为例): 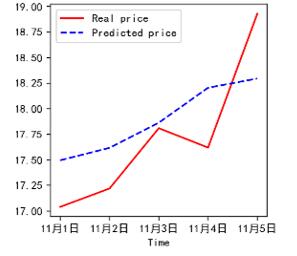 图3 E股票走势预测(示例) 根据预测结果,可以发现B、C、D、E、F、G、I和J股票的股价均呈上涨趋势,而A股价出现下跌;H股近乎持平,没有大幅度的波动。 仅观察趋势可以发现,与真实走势相比,走势预测的准确率约为60%,其中对E股的预测效果最好,而对A股的预测效果较差,这可能与本文所选取的指标不够完善有关。但从整体来看,该模型的预测结果依旧具有一定的参考价值。 接着,本文可以由一周的收盘价预测值计算周涨跌幅预测值,其计算结果如下: 表4 周涨跌幅预测值
可以发现,除了A股以及H股的周涨跌幅预测结果为负数以外,其他股票的周涨跌幅预测结果均大于0。而在其中,G股的周涨跌幅预测结果最好,为5.79%,其次为D股、E股。 2.综合评价选股
前文通过股价的预测计算出来未来一周的涨跌幅预测值,但由于股票的涨跌仍然具有很强的随机性,虽然走势的预测具有一点参考性,但只依据涨跌幅的预测来直接进行投资仍有较大风险。考虑到这一点,为了降低风险,本文考虑公司近期的盈利情况和券商对其的投资评级,再结合涨跌幅预测对股票进行综合评价。 为了对股票进行综合评价,首先需要计算各指标的熵权重,其计算方法在前文已有提及。计算结果如下表所示: 表5 指标权重表
得到各个的权重之后,本文计算出各指标的权重之和,使用TOPSIS算法进行打分,计算得到各个股票得分从高到低分别为:J股、A股、G股、B股、E股、H股、C股、I股、F股以及D股,其综合得分分别为:0.6246、0.6246、0.5766、0.5700、0.5515、0.4884、0.4602、0.4597、0.4361以及0.4040。 观察各个股票的相关数据,可以对各个股票进行分析: (1)J股的收益稳定,虽然在营业收入增长率及净利润增长率上的表现没有特别突出,但其毛利率以及净资产收益率和投资评级都呈现较好的前景,同时其预测出来的股价呈上涨趋势,导致其综合得分最高; (2)虽然A股预测出来的股价出现下跌趋势,但企业处于利好收入状态,特别是其净利润增长率、毛理论以及净资产收益率都十分突出,可以看出公司的发展前景十分良好,因此其投资风险相对较小,值得投资; (3)D股虽然周涨跌幅预测值较好,但其近期的企业表现并不突出,因此排名靠后。 对其他股票也可以进行类似的分析。综上,J股、A股、G股、B股以及E股是本文所选十只股票当中得分前五的股票,因此本文在构建下一周的投资组合时,仅考虑这五只股票。然而观察数据可以发现,A股的周涨跌幅预测中其值为负,因此需要将其剔除掉。最后进行投资决策选取的股票为:J股、G股、B股以及E股。 根据得分确定各股票的投资额度占比为: 表6 各个股票投资额度
得到各股票的投资额度比例之后,我们可以计算得出按这个投资策略进行投资一周之后的收益率为3.3671%,为了验证本文构建的投资组合的合理性,本文将该收益率与上证指数这一周的实际收益率进行对比,本文通过choice金融终端下载得到上证指数这一周的数据,从11月1日到11月5日的收盘价分别为3544.48、3505.628、3498.537、3526.866以及3491.568。 通过该数据可以计算得到,上证指数的这一周的收益率为-0.01493%,小于本文所构建的投资组合的收益率。由此可见,本文构建的投资策略构建模型具有一定的合理性。 五、总结
本文综合考虑了股票历史数据的准确性以及公司近期相关数据对投资者决策的影响,将所选取的指标数据分为了两类:股票数据以及公司数据,选择了十只具有代表性的股票进行分析,使得模型更加精确。首先使用5年的股票数据,利用LSTM预测未来一周各股票的走势以及涨跌幅情况,通过与实际值对比发现预测准确率约为60%。接着将预测出来的涨跌幅作为一个因子,结合公司数据,利用熵值——TOPSIS法进行因子的赋权和股票综合得分的排序,有效地避免了传统赋权方法的主观性和局限性,并以此构建未来一周的投资策略,通过与实际数据对比发现该投资策略的有效性。 然而,本文在指标数据的选取上以及模型的构建上依旧存在一定的局限性。由于本文所选取的指标数量并不足够完善,这可能导致本文的预测结果并不那么理想。与实际情况对比时也可以发现,本模型的预测结果依旧有较大的改进空间。但综合结果来看,本文的模型在一定程度上具有可参考性和准确性,可以为未来的研究奠定一定的理论基础。 参考文献: [1]韩雨薇.基于深度学习的多因子股票风险预测方法研究[D].浙江大学,2020. [2]李文宇.基于机器学习的多因子选股策略研究及实证分析[D].山东大学,2021. [3]宋晨光.基于长短期记忆神经网络模型的股票价格走势预测[D].江西财经大学,2019. [4]韩雨纯.基于改进熵权TOPSIS法的股票投资组合构建与研究[D].山东大学,2021. [5]司守奎,孙玺菁.Python数学实验与建模.北京:科学出版社,2020. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||



 商业银行保本收益
商业银行保本收益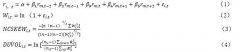 机构投资者持股、
机构投资者持股、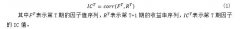 基于LSTM与熵值--
基于LSTM与熵值-- 由CSG证券违规案
由CSG证券违规案 基于招股说明书文
基于招股说明书文 高管经管教育背景
高管经管教育背景 基于业绩承诺与中
基于业绩承诺与中

{kind=link}