
基于PCA-BiGRU-Attention的中国制造业企业财务困境预测研究
|
宋莹莹 (广州理工学院计算机科学与工程学院,广东 广州 510080) 摘要:在新质生产力的背景下,制造业企业面临着更大的风险与挑战,亟需通过技术创新和智能化管理来实现转型升级,以应对市场环境的变化与行业竞争的加剧。因此,制造业企业必须更加精准地预测和应对财务风险,以保障企业的持续健康发展和长远竞争力。本文提出了一种基于深度学习的财务困境预测模型,基于2017-2024年沪深A股制造业上市公司的季度指标数据,结合主成分分析(PCA)、双向门控循环单元(BiGRU)和注意力机制(Attention),通过对2种(PCA-BiGRU-Attention)模型结构的比较,实验结果表明,两种模型在不同时间步和批量大小设置下的准确率存在一定差异,其中PCA-1BiGRU-Attention结构的模型达到了最高的验证准确率(99.6%)。此外,本文通过分别与传统机器学习模型,以及其他深度学习模型进行比较,验证了综合模型(PCA-BiGRU-Attention)的有效性,尤其是在引入注意力机制后,模型性能得到了显著提升。该模型为中国制造业企业的财务困境预测提供了一种高效、精准的解决方案。 关键词:财务困境;主成分分析;双向门控循环单元;注意力机制 一、引言 制造业是我国经济的核心,但在“双碳”目标和数字化转型的压力下,许多制造企业面临财务困境,尤其是上市公司。传统的财务困境预测方法依赖于静态财务比率和基本统计模型,忽视了财务数据的时间序列特性和复杂非线性关系,导致预测精度不足。随着人工智能和深度学习的发展,双向门控循环单元(BiGRU)模型因其能够同时捕捉财务数据的前向和后向信息,成为一种有效的财务预测工具。结合注意力机制(Attention)则能够动态调整模型对关键特征的关注度,提高预测准确性。为提高预测准确性,本文提出了一种结合传统统计方法和深度学习的PCA-BiGRU-Attention模型,实验结果表明,该模型能有效提升制造业公司财务状况的预测精度。 二、文献综述 在全球化和技术创新日益加剧的背景下,中国制造业企业面临的财务困境愈发复杂。传统的财务风险预测方法在处理高维度数据和复杂时间序列时,其性能受到限制,如Z-Score模型依赖于预设的财务比率组合[1],Logistic回归、k最近邻(KNN)在应对非线性和时间依赖性数据时表现出不足[2],随着机器学习方法在财务困境预测中得到了广泛应用,支持向量机(SVM)、贝叶斯方法、随机森林(RF)等模型已被广泛用于处理复杂的财务数据,然而这些方法的性能很大程度上分别取决于所选的核函数,似然函数和先验分布,以及决策树的数量、树的深度、节点分裂的最小样本数等参数的设置[3],无法直接考虑时间序列数据中的序列相关性和趋势,难以捕获长时间序列数据之间的非线性关系。 随着传统机器学习模型应用的局限性,深度学习模型被逐步应用到财务风险预测领域,如、长短期记忆网络(LSTM)和门控循环单元(GRU)等模型,可以更好地处理财务数据中的时间依赖性,并体现出其性能的优越性。Ouyang(2021)采用 Attention-LSTM 神经网络构建了风险预警模型,并将其与 BP 神经网络模型、SVM 模型和 ARIMA 模型进行了对比。研究发现,LSTM 神经网络在短期、中期和长期的平均预测精度上均优于其他模型[4]。而陈超飞,刘浩然(2024)选取了228家制造业上市公司作为样本,采用深度学习技术预测制造业公司的财务风险,研究结果表明,GRU预警模型在性能上优于LSTM预警模型[5]。此外,深度学习在金融和其他行业领域也有着广泛的应用,Liu B等(2024)将环境数据与财务指标融合,结合主成分分析(PCA)、门控循环单元(GRU)和长短期记忆网络(LSTM)构建PCA-GRU-LSTM模型来预测股票价格,对比LSTM、GRU、支持向量回归(SVR)、岭回归(RDG)、Lasso回归、决策树,PCA-GRU-LSTM展示了卓越的预测准确性[6]。Yin H等(2020)提出了一种基于双向门控递归单元BiGRU和注意力机制结合的紧急事件识别模型,可解决传统识别方法的局限性和一般递归神经网可解释性差的问题[7]。综上,表明深度学习方法可以显著提升时间序列数据的预测能力。 目前针对将传统统计方法(PCA)与深度学习方法(BiGRU-Attention)结合用于财务风险预警领域的研究还较少,本文将结合主成分分析(PCA)、双向GRU(BiGRU)和注意力机制(Attention)的混合模型预测财务风险预测。此模型通过将PCA用于特征提取,BiGRU处理时序依赖性,以及Attention提升对关键时间步的关注,并对比传统机器学习模型,展现出卓越的预测性能。 三、研究方法 1.PCA-BiGRU-Attention PCA-BiGRU-Attention模型通过结合PCA降维、双向GRU网络和注意力机制,有效处理复杂的时序数据,PCA具备提取重要性特征的能力,将高维财务指标数据降维为相对低纬主成分,可从公司财务数据中提取核心特征。BiGRU能够捕捉财务时间序列数据中的双向依赖关系,在PCA提取的特征基础上加入双向GRU层,可以学习制造业企业在标识为财务风险前各季度的财务指标变化趋势。注意力机制(Attention)能够在各季度财务数据中关注关键财务特征,并为这些特征动态分配不同时间步的权重,从而提高模型的预测性能。基于这些特点,本文建立了一个用于制造业企业财务风险预测的PCA-BiGRU-Attention模型。该模型主要包括PCA处理的输入层、BiGRU层、注意力机制层、展平层、全连接层和输出层。 2.PCA特征提取 主成分分析(PCA)由Karl Pearson于1901年提出[8],旨在通过较低维度表示高维数据,保留主要特征,实现数据降维和特征提取,从而减少冗余信息并提升模型效率和性能。 在应用PCA时,首先对原始数据进行标准化处理,以确保不同量纲的财务指标对分析的贡献相等。计算标准化后的数据矩阵的协方差矩阵,反映各财务指标之间的相关性。通过求解协方差矩阵的特征值和特征向量,按特征值大小排序,选择前k个主成分,完成数据降维。分析主成分载荷,判断原始财务指标对主成分的贡献,揭示数据中的关键特征,以提高后续模型的效率和性能。 3.双向门控循环单元网络(BiGRU) 双向门控循环单元网络(BiGRU)是结合双向循环神经网络(BiRNN)和门控循环单元(GRU)的一种扩展,专用于处理财务时间序列数据[9-10]。BiGRU通过两个GRU网络分别处理正向和反向信息,捕捉财务序列数据中的双向依赖关系,可更好地理解建模序列中的复杂时序关系。GRU单元由更新门、重置门、候选隐藏状态和最终隐藏状态组成,捕获时间序列的长期依赖性。  4.注意力机制(Attention) 注意力机制最早由Bahdanau等学者于2014年提出,通过在解码过程中动态地聚焦财务时间序列数据的不同时间步和财务指标,对财务时间序列中各个位置的元素赋予不同的权重,以此来更有效地捕捉长时间序列数据之间的依赖关系和前后联系[11]。与双向处理提升对时间序列数据全面理解的BiGRU不同,注意力机制可以动态聚焦增强对长距离依赖信息的捕捉。本文使用基于加性注意力的自定义层的实现,是一种通过为输入财务时间序列中的每个时间步分配不同权重的方式来捕捉序列数据中的相关性和上下文信息的方法,即计算注意力分数、生成注意力权重,然后对输入序列进行加权求和,得到上下文向量。 四、实验 1.样本与指标选取 本文选取2017-2024年265家沪深A股制造业上市公司,数据来自国泰安CSMAR数据库。实验基于TensorFlow深度学习架构,在Windows 10操作系统上运行。ST公司样本为因财务异常(如连续亏损)而被特殊处理的公司,非ST公司样本为同年度未被特殊处理且行业、资产规模相似的公司。T年为被标记为ST的年份,T-1年为上一年,为提前预判财务困境,选取T-3到T-5年每季度的财务指标数据作为预测特征。财务数据指标选取偿债能力、比率结构、经营能力、盈利能力、现金流能力、发展能力和每股收益7大类指标。 2.数据预处理 (1)滑动窗口 本文选取89家ST公司和176家非ST公司,每家公司提取了3年12个季度的财务指标数据,因此分别有1068个ST公司的时间序列点和2112个非ST公司的时间序列点。使用滑动窗口技术,可以生成特征窗口和相应的标签,以便用于后续的分析和模型训练。在12个季度的公司财务数据序列上应用滑动特征窗口技术,如以窗口长度为8为例,创建连续且重叠的窗口,每个窗口包含连续的8个数据点,构成一个时间序列特征集。在滑动过程中,所有窗口将根据后续时间步T的信息被分配相同的标签,该标签反映公司是否为ST公司。这种方法确保同一公司的所有窗口都共享一致的标签,同时充分利用各季度时间序列数据的特征信息。这不仅能有效增加训练样本的数量,还能提高模型的泛化能力。 (2)Smote过采样 使用Smote方法对训练集数据进行增强,在少数类样本(ST样本)周围生成新的合成样本,来增加少数类样本的数量,达到数据平衡的目的。以时间步长8为例,原始训练数据中ST公司的样本数量为352,非ST公司的样本数量为708,使用Smote方法,生成新的合成样本,使ST公司样本数量增加到708,与非ST公司样本数量相等,可以有效增加ST公司的样本数量,减少因样本不平衡带来的偏差。 (3)PCA提取特征 通过使用Python软件对数据进行标准化处理和主成分分析,设置累计贡献率需达到90%,则获取了17个主成分指标。因此,本文选取17个主成分代表公司经营的所有指标。通过计算17个主成分与原始36个指标的相关系数,可得相关系数较高(绝对值>0.5)的指标有:代表偿债能力指标的资产负债率和产权利率,代表结构比率指标的流动资产比率,代表经营能力指标的应收账款周转率和流动资产周转率,代表盈利能力指标的营业利润率,代表现金流能力指标的营业收入现金含量和营运指数,代表发展能力指标的资本保值增值率和所有者权益增长率。尤其最高相关性特征的为应收账款周转率、资本保值增值率、流动资产周转率。 3.PCA-BiGRU-Attention模型的预测效果分析 (1)不同模型结构对比 为了比较不同模型结构、批量次数和时间步的影响,本文设计了一系列实验,并使用相同的数据集进行训练和评估。m1代表PCA+1个BiGRU+1个Attention层,m2代表PCA+2个BiLSTM+1个Attention层。 ①不同模型结构的结果分析 表1展示了在不同时间步(w)和批量大小(batch_size)设置下,m1和m2两种模型的准确率。整体而言,随着时间步的增加,模型的准确率普遍呈现先上升后下降的趋势,特别是在w=7至w=10区间内达到较高的准确率水平。当时间步w=8,批量大小为64时,m1(1BiGRU+Attention)模型的准确率99.6%最高。 从批量大小看,在大多数情况下,两种批量大小设置下的模型性能差异并不显著。然而,在特定情况下(w=8或9时m1模型),批量大小为64的模型准确率普遍偏高一点。 从时间步看,较大的时间步(w=7到w=10)模型表现出了较高的准确率,w=4、5或11时准确率次之,w=12时模型性能急剧下降,直接使用原始数据而不进行滑动窗口处理可能会有过多的噪声或不相关的信息,导致模型难以有效学习。因此,使用滑动窗口等技术可以帮助模型更好地捕捉时间序列中的局部模式,减少信息冗余,提高模型的泛化能力。 表1 m1和m2模型表现对比表 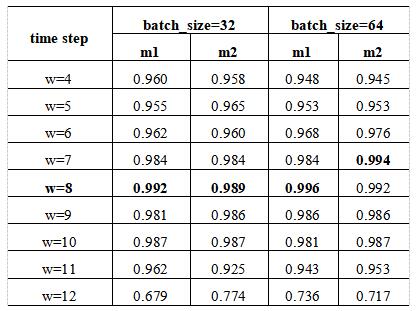 ②最佳PCA-BiGRU-Attention模型的结果分析 在对两种PCA-BiGRU-Attention模型结构进行实验后发现,m1模型(PCA + 1BiGRU + Attention)在时间步长为8、批次大小为64、训练80个epoch时,达到了最高的验证准确率(0.996)。为了评估模型的泛化能力和稳健性,本文采用五折交叉验证法,将数据集分为训练集和测试集,并将训练集随机分为五个子集,每次使用不同的子集作为验证集,计算五次验证的平均准确率,得到模型的平均表现。 表2展示了最佳PCA-BiGRU-Attention模型在不同时间步下交叉验证平均准确率与测试集准确率的分布,平均准确率和测试集准确率在w=7到 w=10之间表现相对一致,尤其w=8时,准确率均为最高,表明模型在这些时间步的泛化能力较好,在w=12 时,测试集准确率明显低于平均准确率,进一步说明模型在不使用滑动窗口处理时泛化性能下降,难以有效学习。 表2 最佳模型交叉验证平均准确率与测试集准确率分布  从最佳模型的性能评价可见,总体准确率为99.6%,表现优秀。模型在预测为Non-ST类的样本中,99.4%为实际Non-ST类,且所有实际Non-ST类样本均被正确预测。在预测为ST类的样本中,100%为实际ST类,实际ST类样本中98.9%被正确预测。该模型在分类问题中表现出色,ST类和Non-ST类样本的精确率和召回率均很高。 (2)不同模型结果对比 表3展示了5种不同机器学习模型和7种不同深度学习模型的准确率对比结果(w=8,batch_size=64),传统机器学习模型分别是逻辑回归模型(LR)、支持向量机(SVM)、随机森林(RF)、高斯朴素贝叶斯(Bayes)和k近邻法(KNN),深度学习模型分别是BP神经网络(BP)、卷积神经网络(CNN)、注意力机制(Attention)、双向长短期记忆网络(BiLSTM)、双向门控循环单元(BiGRU)、双向长短期记忆网络-注意力机制(BiLSTM-Attention)和双向门控循环单元-注意力机制(BiGRU-Attention)。从表3中可以看到,PCA-BiGRU-Attention模型准确率(0.996)表现最佳,其次为BiGRU,而传统机器学习模型的准确率普遍偏低。 从传统机器学习和深度学习模型在ST和非ST数据上的分类性能来看,表3展示了各模型的精度(precision)、召回率(recall)和F1分数(f1-score)指标。总体上,机器学习模型表现一般,尤其在ST类中的表现不如深度学习模型;但在非ST类中,部分机器学习模型如随机森林和KNN表现较好。深度学习模型总体表现出色,特别是结合注意力机制后,模型在ST和非ST类中的表现远超机器学习模型,精度、召回率和F1分数均优异。 表3 不同模型的性能评价表 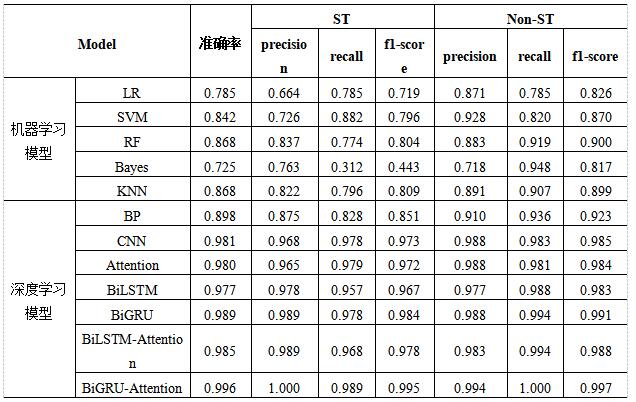 五、结论与展望 本文提出了基于PCA的BiGRU-Attention模型,根据上市公司T-5到T-3近3年12季度的财务指标数据来预测其是否会陷入财务风险。实证结果表明了该模型的高精准性和有效性,本文总结如下: 1.时间步的设置影响模型的准确度:实验表明,较大的时间步(w=7到w=10之间)通常能提升模型的准确性,尤其在w=8时准确率最高,但过长的时间步(w=12)会导致模型性能下降。这可能是直接使用原始数据而不进行滑动窗口处理可能会有过多的噪声或不相关的信息,导致模型难以有效学习。 2.财务特征指标的重要性:通过主成分分析方法,本文确认了对PCA-BiGRU-Attention模型性能影响最大的特征,包括应收账款周转率、资本保值增值率、流动资产周转率等。 3.PCA-BiGRU-Attention模型结构在适配性和有效性方面表现突出:对比BP、CNN、Attention、BiLSTM、BiGRU、BiLSTM-Attention深度学习模型,BiGRU+Attention在五折交叉验证条件下展现了卓越的性能,尤其是在时间步长为8、批次大小为64的配置下,取得了最高的验证准确率(0.996)。这一结果表明,该模型结构能够充分挖掘时间序列数据中的关键特征,具有较强的泛化能力与优异的预测性能。 4.传统机器学习模型表现逊于深度学习模型:传统机器学习模型LR、SVM、RF、Bayes和KNN总体表现一般,尤其在预测ST类公司中,其性能明显不及深度学习模型。 5.注意力机制的有效性:单独的BiLSTM、单独的BiGRU在加入注意力机制后,准确率均能够有效提升。 未来将探索更多维度的特征、超参数优化算法和组合模型结构,考虑融入年报、传媒文本等非结构化指标,尝试使用遗传算法、贝叶斯等优化算法,以进一步提升模型性能。 参考文献: [1]Altman E I. Financial ratios, discriminant analysis and the prediction of corporate bankruptcy[J]. The journal of finance, 1968, 23(4): 589-609. [2]Gareth J, Daniela W, Trevor H, et al. An introduction to statistical learning: with applications in R[M]. Spinger, 2013. [3]Bishop C M. Pattern recognition and machine learning[J]. Springer google schola, 2006, 2: 1122-1128. [4]Ouyang Z, Lai Y. Systemic financial risk early warning of financial market in China using Attention-LSTM model[J]. The North American Journal of Economics and Finance, 2021, 56: 101383. [5]陈超飞,刘浩然.基于深度学习技术的企业财务风险预警研究——以制造业上市公司为例[J].财会研究,2024(1):47-52. [6]Liu B, Lai M. Advanced Machine Learning for Financial Markets: A PCA-GRU-LSTM Approach[J]. Journal of the Knowledge Economy, 2024: 1-35. [7]Yin H, Cao J, Wang G, et al. Chinese Emergency Event Recognition Based on BiGRU-AM Model[C]//Journal of Physics: Conference Series. IOP Publishing, 2020, 1650(3): 032124. [8]Pearson K. LIII. On lines and planes of closest fit to systems of points in space[J]. The London, Edinburgh, and Dublin philosophical magazine and journal of science, 1901, 2(11): 559-572. [9]Schuster M, Paliwal K K. Bidirectional recurrent neural networks[J]. IEEE transactions on Signal Processing, 1997, 45(11): 2673-2681. [10]Cho K. Learning phrase representations using RNN encoder-decoder for statistical machine translation[J]. arXiv preprint arXiv:1406.1078, 2014. [11]Bahdanau D. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
基金项目:2024年广东省社科规划学科共建项目“基于机器学习的企业环境信息披露质量的影响机制研究”(GD24XGL031);2023年广州理工学院课题“基于机器学习的制造业企业财务风险预警模型研究”(2023KY002) |



 基于PCA-BiGRU-At
基于PCA-BiGRU-At 企业ESG漂绿对财
企业ESG漂绿对财 EVA价值评估研究
EVA价值评估研究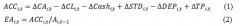 ESG表现与商业银
ESG表现与商业银 核心利益相关者的
核心利益相关者的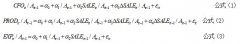 真实盈余管理与企
真实盈余管理与企

{kind=link}